v2.4
- Added factorization of inverse matrix
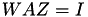 , enabling vector solves using matrix vector mult. instead of forward/backward solves with much better parallel speedup.
, enabling vector solves using matrix vector mult. instead of forward/backward solves with much better parallel speedup.
- Significant improvements in parallel performance of matrix inversion.
- Improved performance of LU, matrix-vector mult., forward/backward solves.
- Added function
nearfield_sparse to extract 𝓗-matrix nearfield as sparse matrix.
- Switched to
adaptive_split_axis as default for clustering.
- Minor Changes:
- Additional options for matrix visualization (colormap, etc.)
- Basic VTK output of block clusters.
v2.3
v2.3.2
- fixed various bugs and race conditions
- extended ctors of various matrix classes to accept optional value type field
- added example on how to assemble block matrices
v2.3.1
- Fixed two bugs in point-wise LU.
- Solver changes:
- Refactored solver classes (no interface changes); added TRichardson to replace TSolver in the future.
- Fixed inconsistent computation of residual norm in solvers. Now Richardson, CG and BiCG will compute standard residual norm, while MINRES and GMRES compute preconditioned residual norm.
- Made initialisation of start vector in solver classes optional (function
initialise_start_value)
- Added function "diagonal" to extract diagonal of a matrix.
- Added example "spectrum" to compute spectrum of graph Laplacian.
v2.3.0
- Fixed issues when solving dense matrices (used in new example for many RHSs).
- Modified THiLoFreqGeomAdmCond: now maximal number of wavelengths per cluster is tested.
- Refactored geometrical clustering classes and partitioning strategies, thereby fixing several issues.
- C++11 changes:
- most object creating functions now return std::unique_ptr,
- replaced typedef by using,
- added iterators for TIndexSet, TNodeSet, TGraph, TProcSet (for range based
for).
- Note: needs at least GCC v4.7 or equivalent!
- Added parameter to algebraic clustering in C bindings to define partitioning algorithm (BFS, multi level, METIS or Scotch).
- Fixed issues with progress bar during factorisation (wrong block count).
- Removed BSP style comminucation functions (MPI only now).
- Finished conversion to new packed_t SIMD type. Using SSE3 instead of SSE2.
- Added lock to TScotchAlgPartStrat because Scotch is not multi thread safe.
v2.2
- Removing implicit reordering of unknowns during matrix-vector multiplication to fix inconsistent behaviour. Please use permutations from cluster trees or 𝓗-matrices to reorder vectors or TPermMatrix to represent permuted matrices instead.
- Speedup improvements for matrix inversion. Triangular inversion and matrix multiplication available in standard user interface.
- Import/export from/to CCS/CRS matrices simplified.
- Simplified (and faster) mutex wrapper.
- Several C++11 changes.
v2.1
- Removing reference counters in BLAS interface due to major performance issue on multi-core (-socket) systems. See BLAS/LAPACK Interface on how to use the modified interface (and avoid errors).
- New, scalable matrix-vector multiplication implemented.
- Using generic datatype for SIMD instructions, thereby enabling generic SIMD algorithms, e.g. for BEM kernels, and fast adoptation of new SIMD instructions, e.g. AVX2.
- Started to use block-wise operations if dense matrices are combined with blocked matrices (e.g. during matrix multiplication) instead of vector operations.
- Removed TVirtualVector (replaced by TScalarVector).
- Fixed issue with MatrixMarket format (leading whitespaces).
v2.0
v2.0.2
- fixed race condition in C bindings
- fixed issue with initialisation of static variables
v2.0.2
v2.0
- Major Changes
- Switched from OpenMP to Threading Building Blocks as interface to shared memory parallelism, thereby also changing most algorithms to task-based parallelism.
- Reducing dependency on external libraries by using C++11 features. Also replacing some classes by default C++ versions (finally removing old code).
- Alternative, non-recursive, level-wise ℋ-LU factorisation based on explicit block dependencies, which provides far better speedup on many-core systems, e.g. Intel MIC architecture.
- New ℋ-LU factorisation algorithm also applicable in distributed environments, yielding better load-balancing (albeit with limited speedup).
- Added support for multiple CPUs to many algorithms, e.g. in clustering, norm computations, matrix-vector multiplication and solves, ℋ²-convertion.
- Minor Changes
- Optimised BEM kernels for Intel MIC architecture.
- Introduced TLinearOperator for operators not supporting TMatrix functionality, e.g. factorised matrices.
- HLIBpro file format changed due to internal changes and due to some bugs in the format. However, backward read compatibility for most files written with earlier versions is kept.
- Added Support for Cairo library, thereby providing PDF output.
- And of course: many smaller feature upgrades and bug fixes.
